在 AI 大模型训练场景中,数据是海量的,模型也是超大的,对于训练大模型会带来很大挑战,比如对算力的需求,对处理大模型的工程复杂度,等等。PyTorch 给出了一种实现方式——FSDP(Fully Sharded Data Parallel),它提供了易用的 API,可以非常方便地解决大模型分布式训练的难题。
FSDP 是在 DDP(DistributedDataParallel)的基础上提出的,首先我们了解一下 PyTorch 的 DDP(DistributedDataParallel) 训练模式的一些特点:
在 DDP 中,核心的能力还是训练数据并行(Data Parallel)。以多机多卡方式为例,每个 process/worker 都会持有模型的一个副本(Replica),通过使每个 process/worker 处理一个 batch 的数据试下并行处理,最后使用 all-reduce 操作对多个不同 process/worker 计算得到的梯度进行累加求和;接着,再将优化器状态、梯度通过跨多个 process/worker 进行复制,使得每个 process/worker 上的模型参数都得到同步更新。也就是说,在 DDP 中并没有实现对模型参数的分片管理,即模型并行(Model Parallel)。
在 FSDP 中实现了模型的分片管理能力,真正实现了模型并行。将模型分片后,在使用 FSDP 训练模型时,每个 GPU 只保存模型的一个分片,这样能够使 GPU 的内存占用比 DDP 方式小得多,从而使分片的大模型和数据能够适配 GPU 容量,更有希望实现超大模型的分布式训练。另外,由此带来的问题是,process/worker 节点之间的通信开销会有一定程度的增加,但是可以通过在 PyTorch 内部有针对性地进行优化来降低通信代价,比如对通信、计算进行 overlapping 能够很好地降低由此带来的网络开销。
FSDP 训练流程
FSDP 实现分布式训练的基本流程,如下图所示:
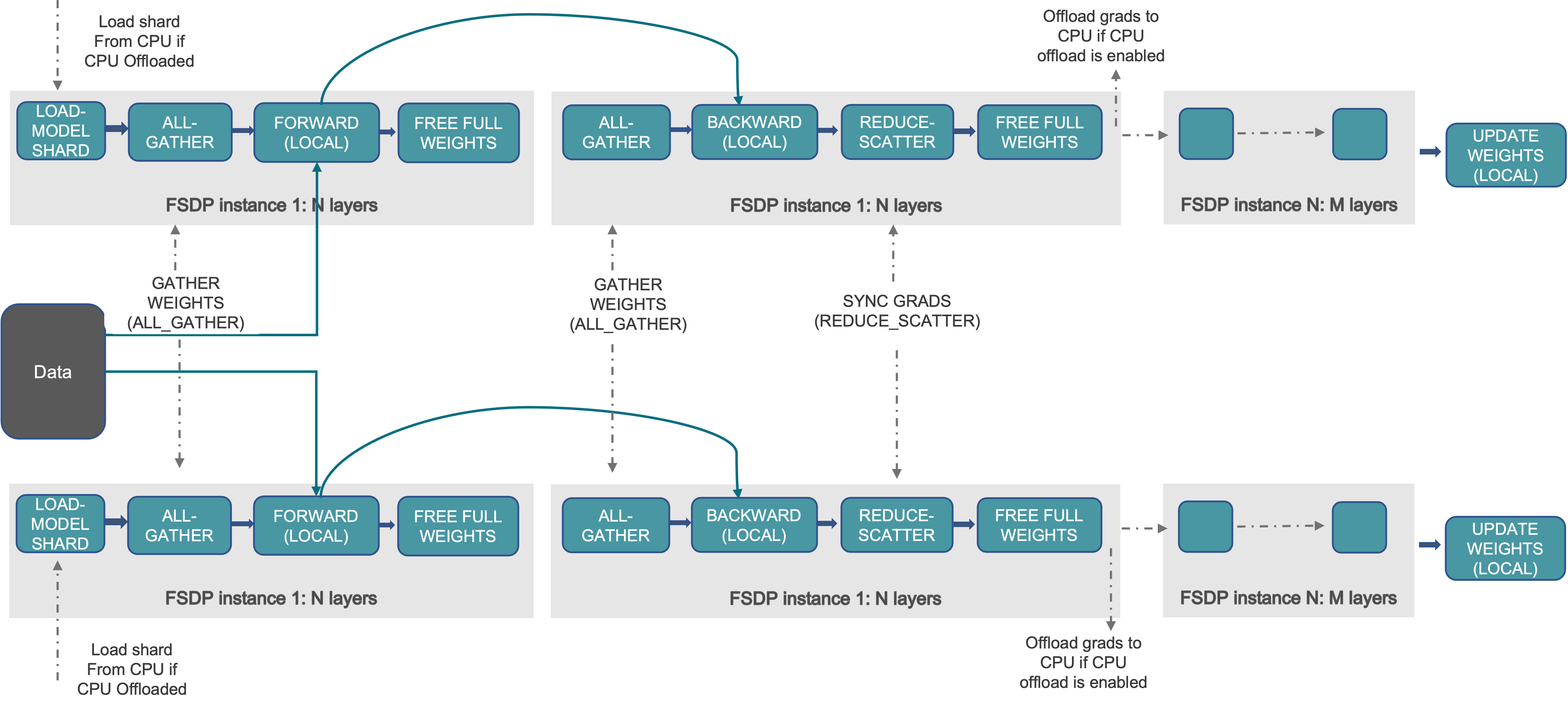
根据上图,可以看到 FSDP 在不同阶段的基本处理过程,如下所示:
01 在初始化阶段
- 分片模型参数,并且每个 rank 只持有它自己的分片
02 在 forward 阶段
- 运行 all_gather,收集所有 rank 上的模型参数分片,生成恢复得到模型参数,以保证满足当前 FSDP Unit 的计算需要
- 运行 forward 计算过程
- 丢掉所有被收集过的其它 rank 上的模型参数分片
03 在 backward 阶段
- 运行 all_gather,收集所有 rank 上的模型参数分片,恢复全部的模型参数,以保证满足当前 FSDP Unit 的计算需要
- 运行 backward 计算过程
- 运行 reduce_scatter,在所有 rank 之间同步梯度
- 丢掉所有从其它 rank 上收集过的模型参数分片
FSDP 模型初始化
首先说一下有关 rank 的概念:
我们直接说 rank,实际上是指全局 rank(Global Rank),rank 是多机多卡集群中对应每个 GPU 的全局编号,比如 4 节点的集群,每个节点有 3 个 GPU,那么 rank 的编号值范围就是 0~11。类似的,局部 rank(Local Rank)就是 local_rank,它的含义是在本机的局部编号,对每个节点来说,有 3 个 GPU,那么每个节点的 local_rank 编号值范围就是 0~3。
01 创建 FSDP 模型
FSDP 模型初始化时,需要通过指定一个 device_id 参数来绑定到指定的 GPU 上,首先模型的 Module 会在 CPU 中初始化,然后加载到 GPU 内。通过指定 device_id 能够保证当 GPU 无法容纳大的模型时,它能够 offload 到 CPU 中,而不至于出现 OOM 的问题。
创建 FSDP 模型,示例代码如下所示:
torch.cuda.set_device(local_rank)
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen,
device_id=torch.cuda.current_device())
可以看到,我们只需要将我们实现的模型(继承自 nn.Module) model,通过 FSDP 进行 wrap 即可,其中指定一些满足需要的配置选项。
下面我们详细说明 FSDP 的 auto_wrap_policy 参数。
02 Transformer Wrapping Policy
auto_wrap_policy 是 FSPD 的一个特性,它能够自动将一个我们自己实现的模型进行分片处理,其中包括对模型参数、优化器状态、梯度进行分片,每个分片都放到一个不同的 FSDP Unit 中。
对于一些架构,比如 Transformer Encoder-Decoder 架构的神经网络模型,包含一些需要被 Encoder 和 Decoder 共享部分,比如 embedding 表,这种情况下,如果直接使用上面的 auto_wrap_policy 参数指定 Wrap Policy 会使神经网络模型中这些共享的部分无法被共享,所以只能把共享的这部分移动到 FSDP Unit 外部去,以便 Encoder 和 Decoder 都能访问这部分。在 PyTorch 1.12 版本中引入了处理这种情况的特性,通过为 Transformer 注册一个 共享 Layer 实现类,就能够使 FSDP 的分片计划(Sharding Plan)实现高效的通信处理。
例如,T5Block 表示 T5 Transformer 层的实现类,它封装了 MHSA 和 FFN 两层,那么初始化 FSDP 模型的示例代码如下所示:
t5_auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
T5Block,
},
)
torch.cuda.set_device(local_rank)
model = FSDP(model,
fsdp_auto_wrap_policy=t5_auto_wrap_policy)
通过打印出 model 就可以看到 FSDP 模型进行分片的结构。
分片原理
FSDP 默认的分片策略(Sharding Strategy)是对模型参数、梯度、优化器状态都进行分片处理,即 Zero3 分片策略,在编程中可以使用 ShardingStrategy.FULL_SHARD 来指定。
对于 Zero2 分片策略,只对梯度、优化器状态进行分片处理,在编程中可以使用 ShardingStrategy.SHARD_GRAD_OP 来指定。如果配置使用 Zero2 分片策略,那么所有的模型参数都会全量加载到每个 rank 对应的 GPU 内,即每个 GPU 持有一个模型的副本。在 forward 阶段和 backward 阶段模型参数都在 GPU 内而不会被 offload 到 CPU,这样就不需要频繁地在多个 GPU 之间传输模型参数分片信息,能够在一定程度上降低 FSDP 集群的通信开销。
设置分片策略,需要在对 FSDP 进行初始化时进行配置,例如指定了 Zero2 分片策略,代码如下所示:
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen,
device_id=torch.cuda.current_device(),
sharding_strategy=ShardingStrategy.SHARD_GRAD_OP)
01 模型分片(Model Sharding)
FSDP 将模型实例(Model Instance)分解成多个较小的单元(FSDP Unit),并且能够使每一个较小的 Unit 被独立处理,在每一个较小的 Unit 内所有参数都会被 flatten 和 分片。被分片的参数在 forward 和 backward 阶段计算之前会通过与其它 rank 进行通信以实现全量参数的按需恢复,这样就能够进行 forward 和 backward 阶段的计算。在计算完成之后,从其它 rank 上收集来的参数分片会被丢掉,以释放当前 rank 上的资源。
FSDP 处理模型分片的总体流程(来自论文《PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel》),如下图所示:
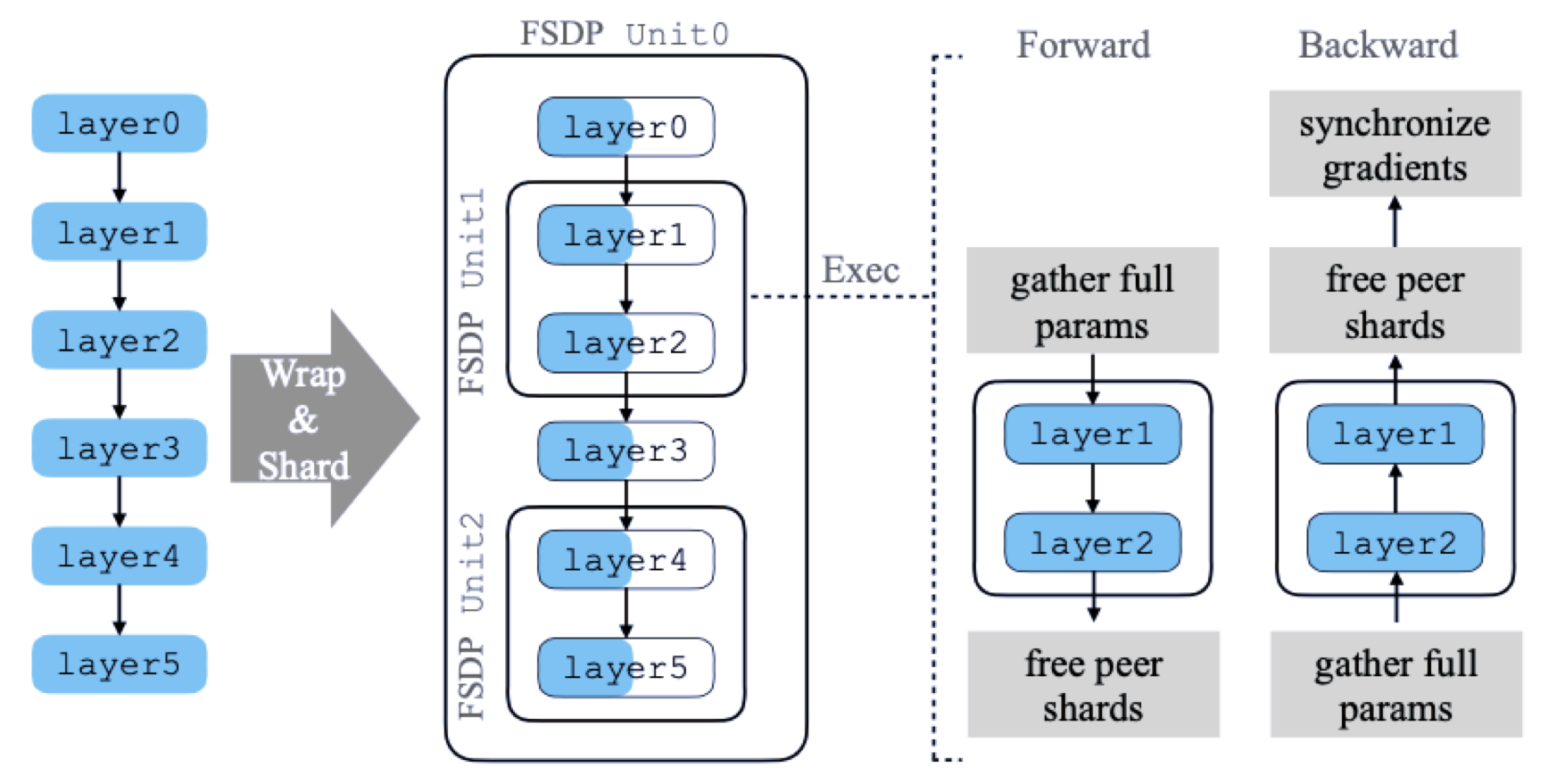
图中模型具有 6 个层,FSDP 将其分解为 3 个 FSDP Unit,分别为 Unit0 = [layer0, layer3]、Unit1 = [layer1, layer2]、Unit2 = [layer4, layer5]。在进行 forward 和 backward 计算之前需要从其它 rank 上收集对应的参数分片,从而保证计算是正确的。
我们以 Unit1 为例来说明如何进行分片处理,该 FSDP Unit 包含了 layer1 和 layer2 两层。
在进行 forward 计算之前,需要将这两层的参数对应于其它 rank 上的分片收集过来使 layer1 和 layer2 两层的参数是 Unsharded,即保证参数是完整的以便进行计算,然后在本地执行 forward 计算过程,完成 layer0 和 layer3 这两层的计算逻辑。当 forward 计算完成后,会释放掉刚刚从其它 rank 上收集到的参数分片,以降低内存空间的占用。每一轮 forward 计算,FSDP 一次只需要处理一个 Unit 的参数即可,而其它的 Unit 仍然保持其参数的分片状态。
对于 backward 计算的过程也是类似的,它会先计算 layer2,再计算 layer1,在开始计算 layer2 层之前,FSDP 会从其它 rank 上收集 layer2、layer1 层的分片参数,恢复得到这两层完整的参数后,Autograd 引擎会继续完成 layer2、layer1 这两层的计算,随后释放掉从其它 rank 上收集过来的参数分片。接着,FSDP 会进行 reduce-scatter 操作对梯度进行累加并分片。当 backward 计算结束后,每个 rank 都只保存了模型参数和梯度的分片部分。
02 集合通信(Collective Communication)
FSDP 的分片过程,通过使用 all-reduce 进行 Collective Communication 进行梯度的分片与收集操作。可以将 all-reduce 分解为 reduce-scatter 和 all-gather 两个操作,能够更直观看到模型参数是如何分片与收集的,如下图所示:
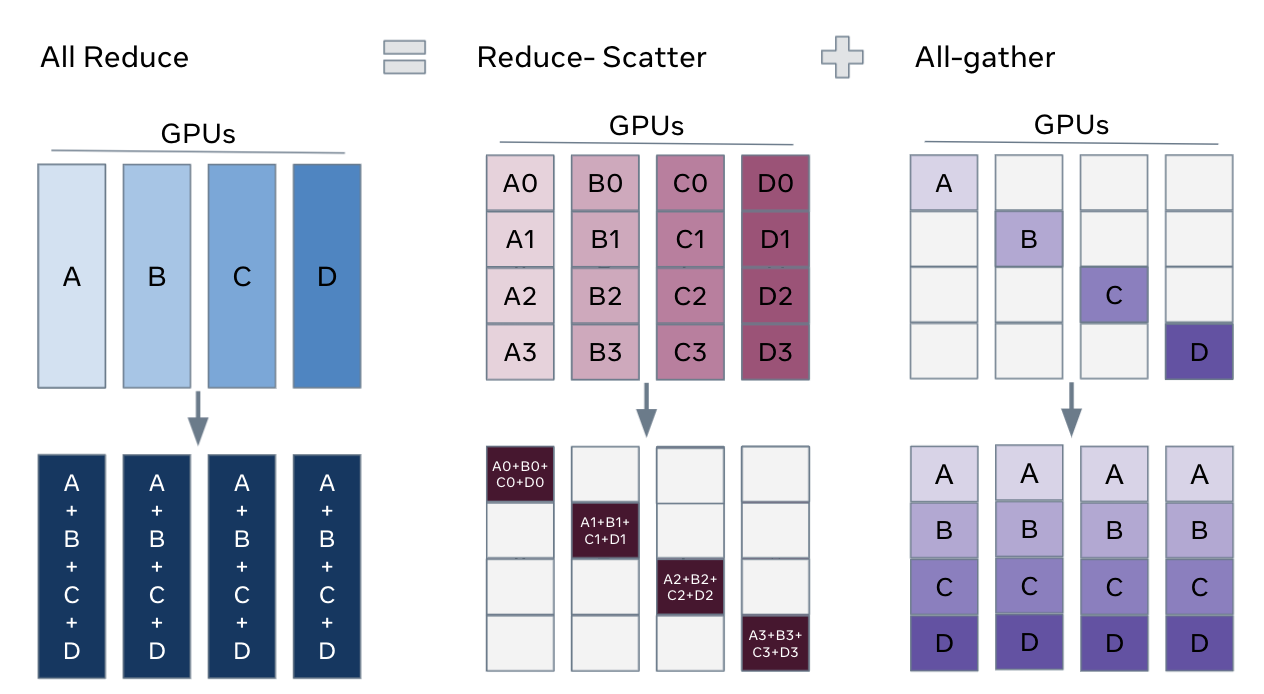
下面对 reduce-scatter 和 all-gather,以及 all-reduce 操作进行说明:
- all-gather
在一个 FSDP Unit 中进行 forward 或 backward 计算之前,每个 rank 会从其它的 rank 上收集所有要使用的分片参数(Sharded Parameters),从而得到完整的参数(Unsharded Parameters),保证能够对当前 FSDP Unit 中的一组 layer 进行正确计算。
- reduce-scatter
在进行 backward 计算之前,会首先进行 all-gather,得到一个 FSDP Unit 需要的完整参数,然后进行 backward 计算。完成 backward 计算之后,通过 reduce-scatter,先对梯度进行 reduce,使每个 rank 上对某个参数分片进行梯度累加得到该参数的完整值,比如 A 在某个 rank 上得到了 A 的全部分片 A1、A2、A3、A4,进行 dist.ReduceOp.SUM 以后得到了完整的参数 A,同理其它各个 rank 上分别都有了完整的参数 B、C、D;然后再通过 scatter 将更新后的参数分片分发给每个 rank,保持各个 rank 仍然只管理自己持有的那部分参数分片,例如得到完整参数 A 的 rank,它还是负责管理更新后的 A0、B0、C0、D0 这 4 个分片,如果其它的 rank 在计算之前需要某个分片则会通过 all-gather 请求得到 A0、B0、C0、D0 这 4 个分片,其它的情况也是类似的。
- all-reduce
经过上面 all-gather 和 reduce-scatter,下一轮在进行 forward 计算之前,就会再次通过 all-gather 得到完整的参数,即每个 rank 上都有了这一 forward 阶段计算所需要的 A、B、C、D 完整参数,然后进行正确的 forward 计算。
总结
目前,分布式训练的 FSDP 模式的架构实现的还比较简单,对一些要求不是很复杂的场景可以解决大规模分布式训练,尤其是对于大模型场景下模型无法直接放到单个 GPU 内进行处理的情况,采用模型分片的方式能够很好地实现大模型的分布式训练。我看开发社区关于 FSDP 的架构设计还在讨论和不断演进完善中,感兴趣的话可以查看 PyTorch 开发社区关于分布式训练相关的一些讨论:
- Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First Principles
- FSDP & CUDACachingAllocator: an outsider newb perspective
另外,关于如何上手一步步实现 FSDP 分布式训练模型的编程,可以参考官方文档:https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html#how-to-use-fsdp
参考资源
- https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html
- https://pytorch.org/tutorials/intermediate/FSDP_adavnced_tutorial.html
- https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
- https://dev-discuss.pytorch.org/t/rethinking-pytorch-fully-sharded-data-parallel-fsdp-from-first-principles/1019
- https://engineering.fb.com/2021/07/15/open-source/fsdp/
- PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel

本文基于署名-非商业性使用-相同方式共享 4.0许可协议发布,欢迎转载、使用、重新发布,但务必保留文章署名时延军(包含链接:http://shiyanjun.cn),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请与我联系。
作者你自己看看你写的通顺吗,图layer一半有颜色一半没颜色,画的啥东西
哦,你说的那个图应该是从我 PyTorch FSDP 论文里面截的图,不是我画的,到底哪里影响了你呀,可以说一下哈