GPT 系列模型对应的论文及 Tech Report,参考如下表所示:
下面,对 GPT 系列每一个模型的网络架构和相关优化技术要点进行详细说明。
GPT-1 模型
GPT-1 模型的基本架构,以及基于预训练模型进行微调应用于下游 NLP 任务的流程,如下图所示:

GPT-1 模型的训练过程,可以分为两个阶段:
- 无监督预训练(Unsupervised Pre-training)
GPT-1 模型采用了基于自注意力(Self-Attention)机制的 Transformer 模型,模型架构只包括解码器(Encoder)部分。
在预训练过程中,使用了掩码自注意力(Masked Self-Attention)机制实现自注意力计算,在计算自注意力权重时,模型只能关注当前位置及前面的位置,而不考虑未来的位置。
GPT-1 预训练任务的目标是学习语言的通用表示,而不是将输入序列映射到目标序列,所以 GPT-1 模型选择了只采用解码器(Encoder)部分的神经网络架构。
- 有监督微调(Supervised Fine-tuning)
GPT-1 模型预训练完成后,模型为了能够更好地支持下游多种不同类型的 NLP 应用任务,模型需要进行有监督微调,即根据具体 NLP 任务的需求对数据进行标注,然后在进行模型的微调训练。模型微调的过程也称为迁移学习,利用已经预训练好的模型,能够节省巨大的计算成本,而且能够将预训练得到的模型的知识能力迁移到下游应用场景中,比如推理(Inference)、情感分析、相似度计算(Similarity Computation)、多项选择(Multiple Choice)、文本分类(Text Classification)、对话问答(Chat Q/A)等。
在微调阶段,对特定任务的输入进行转换时,需要保证预训练阶段使用的词汇表和编码方案与微调阶段保持一致,否则得到的微调模型使用时会出现无法保持一致的语言表示、理解能力。
采用 BPE(Byte-Pair Encoding)分词算法
GPT-1 采用 BPE(Byte-Pair Encoding)分词算法,它是一种基于数据压缩的可逆分词(Reversible Tokenization)方法,可以有效地减小词汇表的大小,从而减少模型需要学习的参数量。
BPE 分词算法的基本步骤,如下所示:
- 建立初始词表:将每个词/字符加入词表;
- 统计字符出现频率;
- 合并高频的字符对;
- 重复上面步骤 2 → 3。
最后,将原始的文本压缩成立一种更短的形式,同时还保存了词/字符间频繁出现的模式。
BPE 算法非常适合处理英文文本,而中文和英文完全不同,处理中文分词会更加复杂。
采用掩码多头注意力机制
GPT-1 采用了掩码自注意力(Masked Self-Attention)机制,掩码的含义是,用来控制模型在处理序列数据时忽略无效的部分,具体来说就是一个与输入序列的长度相同的、由 0 和 1 组成的矩阵,其中 0 表示对应位置是无效的,1 表示对应位置是有效的。掩码自注意力,是将输入序列中右侧部分的无效位置屏蔽掉,这样在进行计算时无效位置的权重就会变得非常小,从而将其对最终结果的影响降到最小。通过使用掩码自注意力机制,使模型在训练过程中能够更好地捕捉到序列中的有效信息。
对于掩码多头注意力(Masked Multi-head Attention)机制,我们可以通过下图来说明它的处理机制:

上图中,使用了一种 Look Ahead Masking 的方法,对于未来出现的 token 会将它们的权重值置为无效,而对其它已经出现过的 token 使用正常的多头注意力机制来计算权重。
GPT-2 模型
GPT-2 也采用了只包含解码器(Decoder)部分的 Transformer 架构,而且是单向的,它使用了不同规模的参数量进行模型的训练,如下图所示:

如图所示,总计包括了 4 种不同参数规模的模型:
- SMALL:117M 参数
- MEDIUM:345M 参数
- LARGE:762 M 参数
- EXTRA LARGE:1542M 参数
对于每一种参数规模的模型,对应的超参数情况,如下图所示:

自注意力层前后都进行层归一化(Layer Normalization)
与 GPT-1 不同,GPT-2 对每个 Encoder Block 的自注意力层,前后分别都进行了层归一化(Layer Normalization)操作,即在每一层的输入和输出都有一个 Layer Normalization 子层,如下图所示:

在输入自注意力层之前新增 Layer Normalization 层,能够将输入数据的均值和方差分别标准化为 0 和 1,使数据在不同的尺度上保持一致。而且,这种策略能够缓解梯度消失和梯度爆炸的问题。同时,层归一化有助于优化器在更新权重时找到合适的方向,提高模型的训练稳定性和收敛速度。
采用 BBPE(Byte-level BPE)分词算法
GPT-2 采用了 BBPE(Byte-level BPE)分词算法,它是 BPE 算法的一种变体,从字符级别扩展到字节(Byte)级别。
BBPE 可以跨语言共用词表,压缩词表的大小,对于同样的训练集,BBPE 模型可能比 BPE 模型的表现更好。然而使用 BBPE 算法使得序列比 BPE 更长,导致训练/推理时间会更长。
采用相对位置编码(Learnable Relative Positional Encoding)
GPT-2 采用了一种可学习的相对位置编码(Learnable Relative Positional Encoding)方法,这种方法不仅考虑了输入数据 token 之间的绝对距离,还关注了它们的相对位置关系,从而能够更好地捕获长程依赖关系,提高模型的性能。
采用掩码自注意力机制
GPT-2 采用了掩码自注意力(Masked Self-Attention)机制,下图对比了自注意力(Self-Attention)与掩码自注意力(Masked Self-Attention)之间的区别:

在预训练阶段,模型训练过程中会学习语言的通用表示,掩码自注意力(Masked Self-Attention)能够保证模型在生成文本时只关注当前位置以及之前位置的上下文,最小化无效部分带来的影响,有助于得到的模型遵循自然语言的生成规律。
在 GPT-2 模型训练中,使用单向语言建模任务来学习文本的上下文信息,这使得 GPT-2 在文本摘要、机器翻译、对话生成等 NLP 任务上表现出色。
零样本学习(Zero-shot Learning)
在 GPT-2 中,多任务学习在无监督预训练阶段学习了大量的自然语言文本,所以 GPT-2 模型的零样本学习能力,可以直接迁移到下游的不同应用领域。下面是 GPT-2 在多任务情况下零样本学习结果表现,如图所示:

GPT-3 模型
GPT-3 模型通过预训练过程训练,得到预训练模型,下游各种应用任务基于该预训练模型,不需要任何的进行梯度更新或模型微调,只需要基于上下文学习(In Context Learning,ICL)来适应不同类型的任务,而且表现非常好,这离不开基础预训练模型的优异性能。
GPT-3 模型,是基于优化的类 Sparse Transformer 解码器架构的超大规模模型,拥有参数量 1750 亿。这种类 Sparse Transformer 模式在 Transformer 的各层中交替使用密集(Dense)和局部带状稀疏(Locally Banded Sparse)注意力模式,大大提高了 GPT-3 处理长序列的计算效率。GPT-3 模型的架构,如下图所示:

训练 GPT-3 模型,使用了 5 个数据集:Common Crawl (filtered)、WebText2、Books1、Books2、Wikipedia(其中未公开 Books1 和 Books2 的数据来源),各个数据集的信息如下图所示:

GPT-3 模型训练了 8 种不同尺寸的模型,训练过程中分别使用的超参数情况,如下图所示:

其中,最大的 GPT-3 模型有 1750 亿参数。
引入稀疏注意力机制
GPT-3 在 Transformer 网络的各层中引入了交替的密集和局部带状稀疏注意力模式,这种方式能够使 GPT-3 更有效地处理长序列,从而减少计算复杂度及内存空间占用,因此提高了模型的可扩展性。
局部带状稀疏(Locally Banded Sparse)注意力的计算过程如下:
- 设置 Window 大小,确定每个 token 能够关注的上线文范围
- 基于 Window 大小范围内的 token 创建自注意力矩阵
- 计算局部带状注意力
使用上下文学习(In Context Learning,ICL)方法
为了避免在微调阶段调整模型参数,GPT-3 模型更加重视基于内容的学习方法:在任务适应阶段,模型采用了零样本(Zero-shot)、单样本(One-shot)和少样本(Few-shot)的学习策略,突破了传统微调方法的限制。与传统微调方法相比,零样本(Zero-shot)、单样本(One-shot)和少样本(Few-shot)的学习策略具有非常明显的优势。
零样本(Zero-shot)学习,是指训练模型在没有接触过任何与目标任务相关的标签数据的情况下,仅凭借在预训练阶段学到的知识来解决问题。使用这种策略,模型需要理解任务描述,并在没有任何样本的情况下完成下游任务。GPT-3 模型在零样本(Zero-shot)学习方面表现优异。
单样本(One-shot)学习,是指在仅给定一个与目标任务相关的示例样本的情况下进行推理。使用这种策略的关键是,让模型从有限的信息中快速学习并适应新任务。GPT-3 模型可以在极少的标签数据情况下快速适应新任务,降低了在特定任务上进行监督学习所花费的时间和训练代价。
少样本(Few-shot)学习,是指训练模型在给定少量与目标任务相关的标签样本示例后进行推理。GPT-3 模型在少样本学习任务上的表现也很好,这是因为 GPT-3 预训练模型已经具有很强的泛化能力,可以在只具有少量标签数据的情况下经过推理得到高质量的结果。
GPT-3 在 LAMBADA 数据集上测试了模型的性能,结果如下表所示:

通过上表可见,GPT-3 模型极大地改进了在 LAMBADA 数据集上的性能,相比于 SOTA 方法。在 StoryCloze 和 HellaSwag 两个数据集也获得了比较可观的性能。
GPT-3.5 模型
从 GPT-3 开始,OpenAI 开始采用部分闭源策略,一些关键的技术细节并未全面公开。
ChatGPT 模型是基于 GPT-3.5 进行构建和改进的,而 InstructGPT 则建立在 GPT-3 之上,它们都通过引入人工反馈机制来对原始模型进行微调和优化。基于 GPT-3 微调得到的模型是 GPT-3.5-Turbo,然后又有了 InstructGPT 模型,它也被称为 GPT-3.5。
GPT-3.5 引入了 GitHub 等代码数据集,以及 StackExchange 等对话论坛和视频字幕数据集。GPT-3.5 模型在训练过程中也使用了大量的数据集,这些数据集的多样性和丰富性保证了模型能够更好地理解和生成各种类型的文本,从而使模型在各种应用场景中都具有较好的表现。
为了降低下游使用预训练模型的成本,提高基于预训练模型更容易适应下游各种类型任务,基础预训练模型的性能非常关键,在数据集方面可能需要从如下几个角度来不断优化:
- 提高预训练数据的数量与质量
- 对预训练数据集进行去重处理
- 提高预训练数据集的多样性
InstructGPT 主要通过微调(fine-tuning)的方式,来更好地对齐人类的意图。为了训练 InstructGPT,OpenAI 训练了 3 个模型(模型参数分别为 1.3B、6B、175B),模型架构与 GPT-3 相同,这三个模型如下所示:
- SFT 模型(Supervised Fine-Tuning)
- RM 模型(Reward Modeling)
- RL 模型(Reinforcement Learning)
InstructGPT 数据集
InstructGPT 使用的数据集概要情况,如下表所示:

SFT 数据集和 RM 数据集,训练集和验证集都使用了 OpenAI API 客户调用获取,以及标注人员手动编写的 Prompt 提示数据,而 PPO 数据集都是使用 OpenAI API 客户调用获取的数据。
另外,InstructGPT 训练也考虑了标注数据的多样性,收集到的训练数据跨多个不同的类别,如下表所示:

上表中包含了 RM 数据集和 SFT 数据集跨多个不同类别,PPO 数据集也是基于类似的要求准备的,分布的类别具有多样性的特点。
InstructGPT 训练过程
上面三个阶段的微调方法和过程,可以通过下图给出的步骤来简要说明:

分别对应于上面提到的三个模型(SFT 模型、RM 模型、RL 模型),InstructGPT 的训练过程主要包括如下三个步骤:
Step 1: Collect demonstration data, and train a supervised policy.
Step 2: Collect comparison data, and train a reward model.
Step 3: Optimize a policy against the reward model using PPO.
下面详细说明各个阶段具体是如何进行训练的:
1. 有监督微调(Supervised Fine-Tuning)
有监督微调使用了 SFT 数据集,该数据集的来源如下:
- 通过 OpenAI 的 API 调用得到 Prompt 提示数据
- 专门的标注人员编写的 Prompt 提示数据
基于上面两种数据来源,最终用于有监督微调的训练数据有 13K 个 Prompt 提示数据条目,其中训练数据中也包括 Prompt 提示对应的答案。
有监督微调阶段,使用了 SFT 数据集对预训练的 GPT-3 模型进行了微调,这个经过微调的模型被称为 SFT 模型,参数为 1750 亿,它是一个具有基本预测能力的 Baseline 模型。
根据论文中描述,有监督微调过程采用了余弦学习率衰减策略,训练了 16 轮,同时为了防止过拟合,设置残差的 Dropout 参数值为 0.2。训练 SFT 模型使用了 13K 个样本,由于训练数据时候可能会导致微调的模型过拟合,而 InstructGPT 并不会直接使用该微调 SFT 模型,而是作为一个 Baseline 模型以支持另外两个模型的训练。
2. 奖励建模(Reward Modeling)
奖励建模阶段使用 RM 数据集,该数据集通过 OpenAI API 获取,以及标注人员编写,共计提供了 33K 个 Prompt 提示数据条目。
在考虑到人类不可能为所有问题编写答案的情况下,训练一个奖励模型用于理解人类的偏好是很有必要的。InstructGPT 基于 GPT-3 微调模型(即 SFT 模型),训练了一个奖励模型,该模型相对较小,具有 60 亿参数,较小的模型能够节省一定的算力资源。
奖励建模(Reward Modeling)的核心思想是,通过人工排序信息将其转化为可优化的奖励分数,并利用这些分数来调整 GPT-3 的模型参数。为了实现这一目标,InstructGPT 采用了一种创新的奖励建模算法,如下图所示:

在使用 RLHF 学习的情况下,排序提供了一种弱监督信号,也就是说是以人类的偏好作为奖励。排序能更好地评估每个答案的质量,从而提高模型的泛化能力,最终奖励模型逐渐学会了按照人类偏好进行打分。
3. 强化学习(Reinforcement Learning)
强化学习训练阶段,使用 PPO 数据集,该数据集只是通过 OpenAI API 获取的 Prompt 提示数据,共计 31K 个,被用于微调 SFT 模型,将标注人员提供的不带标注的提示,输入 SFT 模型,此时不再让人类来反馈,而是直接使用前面训练得到的 RM 模型来对 SFT 模型的推理结果进行评估反馈,从而不断优化模型参数。然后,根据优化后的策略再次生成推理结果,再由 RM 模型进行评估反馈,持续优化 SFT 模型参数,如此循环持续优化策略至最优。
在强化学习过程中采用了 PPO 算法,SFT 模型是前面第一步中 “有监督微调” 中经过微调的 GPT-3 得到的,该 SFT 模型作为 PPO 算法的策略网络。基于 PPO 算法的 InstructGPT 强化学习过程,如下图所示:

对于每个 Prompt 提示,输入到当前的强化学习模型中,生成一个对应的输出 y;接着,将 (x,y) 输入到 RM 模型中,以计算评估其得分。通过优化如下目标函数:

使新训练得到的 RL 模型,能够生成人类认为排序较高的推理结果。
GPT-4 模型
GPT-4 是一个多模态大模型(Large Multimodal Model,LMM),能够处理输入的文本和图片,并生成文本输出,GPT-4 的性能和效果,显示出其卓越的生成和理解能力。由于 OpenAI 并没有公布 GPT-4 的技术细节,只能通过发布的 GPT-4 技术报告来粗略推测。
GPT-4 的核心原理是,基于 Decoder-only 的 Transformer 自回归语言模型,即通过给定的文本序列,预测下一个词的概率分布,从而生成新的文本。GPT-4 采用了大规模的无监督预训练和有监督微调的方法,即先在海量的通用文本语料上进行预训练,学习文本的通用特征和规律,然后在特定的下游任务上进行微调,学习任务的特定知识,从而实现对任意文本的生成和理解。
基本特点
- 规模巨大,参数众多。
GPT-4 拥有超过 1000 亿个参数,是 GPT-3 的 3 倍,是 GPT-2 的 300 倍,是 GPT-1 的 3000 倍。
- 数据丰富,覆盖广泛。
GPT-4 使用了超过 2.5 PB 的数据进行预训练,其中包括了 Common Crawl(1.8PB)、Wikipedia(60TB)、Reddit(40TB)、BooksCorpus(30TB)、Open Images(20TB)、LibriSpeech(10TB)、YouTube(10TB)等多种类型和格式的数据。GPT-4 的数据覆盖了文本、图像、音频、视频等多个领域,涵盖了人类的各种知识和信息,显示出其广泛的适应和理解能力。
- 模型通用,任务多样。
GPT-4 采用了通用语言模型的架构,即不针对特定的任务或领域进行优化,而是通过大规模的预训练,学习文本的通用特征和规律,然后通过少量的微调,适应不同的下游任务和领域。GPT-4 可以处理多种类型和格式的数据,如文本、图像、音频、视频等,也可以处理多种任务,如聊天机器人、搜索引擎、写作助手、教育辅导、娱乐创作、知识问答等,显示出其灵活的生成和理解能力。
- 性能卓越,效果惊艳。
GPT-4 在多个性能基准测试中,都取得了令人瞩目的成绩,超越了人类水平或现有最先进的模型。
例如,在 MMLU(大规模多任务语言理解)测试中,GPT-4 以 95.0% 的成绩超越了人类专家,这一测试综合了数学、物理、历史等 57 个科目;在 UltraMMMU(超大规模多模态语言理解)测试中,GPT-4 以 75.4% 的成绩超越了 GPT-3.5,这一测试综合了文本、图像、音频、视频等多种类型和格式的数据 。
技术方案
Zero-shot 及 Few-shot 学习能力
Zero-shot 以及 Few-shot 学习能力的提升,理论依据最可能是由于 LLM 模型的涌现能力(Emergent Ability)。
涌现能力(Emergent Ability)是指模型在训练过程中,自动地学习到一些高级的、复杂的功能或行为,而这些功能或行为并没有被直接编码或指定。这种能力使模型能够在处理新的、未知的任务时表现更加出色,因为它是通过自适应地学习获得了新的功能或行为,而不需要重新训练或修改模型。
模型产生涌现能力,主要取决于 4 分方面:
- 模型参数量超大。GPT-4 很可能使用一些策略提高了模型的推理速度,所以文本模型参数大概是千亿级别甚至非常接近万亿级别。如果 GPT-4 使用了 CLIP 做图像编码,据 OpenAI 论文公布,目前最大的图像编码器是扩大了 64 倍的残差网络,那么 GPT-4 的图像编码大概有 16 亿。当然也可能采用其它图像编码结构,比如基于 Transformer 的 KOSMOS-1 就是一个不错的选择。
- 模型的架构。GPT-4 大幅提升了对长文本的处理能力,有可能使用了 Transformer-XL 或 Sparse Transformer 架构;GPT-4 更有可能是在 ChatGPT 的基础上迭代而得到的;GPT-4 还可能使用了原生的 Transformer,并增加了更多的层数,head 数量以及隐藏层节点数。GPT-4 支持多模态能力,可能是基于多模态算法 CLIP 实现的图像编码器;另外,微软的 KOSMOS-1 也展示出了和 GPT-4 类似的多模态语言模型能力,GPT-4 有可能借鉴了 KOSMO-1 的思想。
- 高质量的训练数据。
- 先进的训练策略。GPT-4 基本保持了和 ChatGPT 相同的训练策略,遵循了“预训练+提示+预测”的范式,改进包括:引入基于规则的奖励模型(Rule Based Reward Model,RBRM)、引入了多模态的提示学习、引入了思维链(Chain of Thought,COT)。
逻辑推理能力
OpenAI 为了提升 GPT-4 的推理能力,很有可能使用了近年来 LLM 非常重要的思维链(Chain of Thought,COT)以及自提升(Self-Improve)方法。
思维链(Chain of Thought)是指人们在进行思考时,由于某个观点、想法或感知刺激而引发的一系列相关思维关联,这些关联可以通过人们的记忆、经验、知识、情感和意识等方面来建立和加强,最终形成了一个有机的思维链,帮助人们理解和解决问题,做出决策和行动。
LLM 和思维链的结合,可以让模型使用无监督的数据进行自我提升(Self-Improve),计算过程如下图所示:
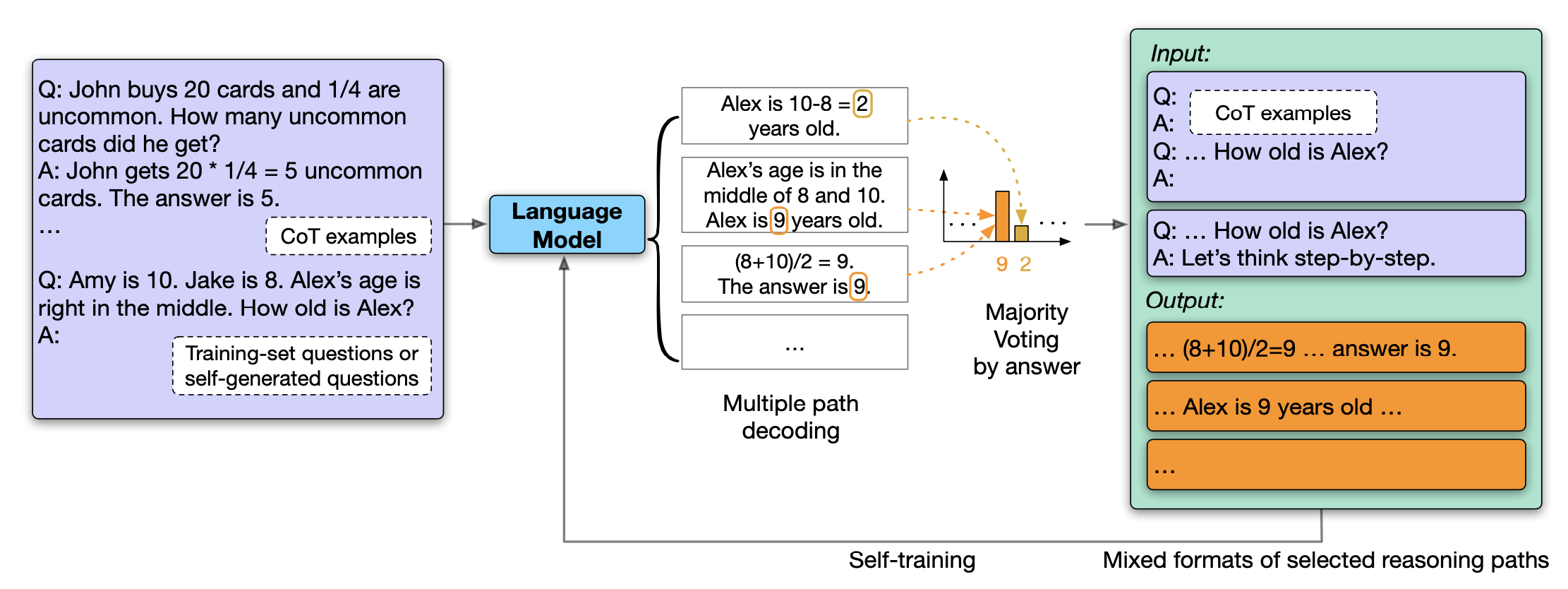
计算过程描述如下:
- 基于思维链构建 Prompt 提示;
- 根据不同的温度系数,模型生成多个不同的包含推理过程的 Path;
- 使用投票的方式选择最有可能的正确答案;
- 将包含这个正确答案的所有 Path 用来优化 LLM。
理解图像能力
GPT-4 支持图像格式的图表输入,OpenAI 的多模态算法 CLIP 可以通过对比学习将图像和文本映射到同一特征空间,那么结合 CLIP 的图像编码器便可以实现 GPT-4 的图像输入,训练一个可以和 GPT 的文字特征对齐的图像编码器,然后将 CLIP 的图像编码器的输出作为图像 token,最后再加一个 Embedding 层将这个 token 编码为 GPT-4 的特征向量。

GPT-4 还可以理解包含了很多细节的学术图片。在学术图片中,图中代指的符号,目标之间的位置关系都是十分重要的,如果 GPT-4 仅仅通过一个图像编码就能捕获这些细节信息,那么这个图像编码器一定也展现出了非常强的涌现能力,这个图像编码器也大概率是千亿规模的参数量。
更安全的文本生成能力
GPT-4 的技术报告中指出,文本模型会存在下面几类的风险输出:幻觉、有害内容、歧视、虚假信息、暴力、隐私、网络安全等。GPT-4 聘请了 50 余名来自不同领域专家扮演红队进行对抗测试。红队的工作是提出有危险性的问题,以测试 GPT-4 给出的输出,并尝试攻克它。通过领域专家的对抗,OpenAI 也采集了大量不同方向的领域专家数据来提升 GPT-4 的安全性。
幻觉(Hallicination)是生成模型都非常难以解决的问题,它指的是模型产生的荒谬的或者不真实的内容。GPT-4 采用了两个策略来解决幻觉问题:
- 利用 ChatGPT 的数据进行训练;
- 采用 NLP 技术来检测模型产生的幻觉样本,包括自动评估和人工评估。
对于可能出现的其它风险输出,OpenAI 并没有详细的介绍它的技术方案,不过从他们的技术方案中,我们可以看出他们大概使用了下面几类方法:
- 使用 RBRM(Rule-Based Reward Model)来检测可能出现的风险;
- 通过提示学习让模型学习拒绝回答此类问题;
- 利用红队发现这些可能存在的问题;
- 过滤训练数据,删除可能触发风险问题的样本;
- 训练奖励模型,让模型惩罚有危害的输出内容。
更强的编程能力
GPT-4 在编程能力上比 ChatGPT 有了巨大的提升,一方面可能使用思维链掌握了更强的逻辑分析能力,另一方面有可能借鉴了 OpenAI 著名的代码生成算法 CodeX。CodeX 是 GPT-3 在代码生成领域的衍生版本,也是 Copilot 插件背后的基础算法。CodeX 采用了 GPT 系列 Decoder-only 的 Transformer 架构体系,模型的参数量有从 12M 到 12B 等多个不同的版本。CodeX 的训练分成预训练和微调两个阶段:
在预训练阶段,OpenAI 从 Github 上爬取了大量的 Python 文件,经过清洗后得到了一个大小为 159GB 的训练集;
在微调阶段,OpenAI 从竞赛网站、面试网站、Github 的单元测试脚本中收集了大约 40000 条数据。
CodeX 和 GPT-4 都是 GPT-3 的下一代模型,让 GPT-4 使用 CodeX 现成的思想和数据,并提高模型的编程能力,是非常合理的。
多语言能力
GPT-4 的在其它语种上能力的大幅提升,可能使用的技术方案如下:
- 提升了其它语种的训练数据;
- 更大规模的模型让 GPT-4 在小语种上涌现了更多的能力;
- 加入了针对小语种的任务,例如利用现有平行语料构建基于提示学习的机器翻译任务,使用机器翻译引擎将部分数据翻译成小语种等。
处理更长序列的能力
这里的长序列包含两个方面,一方面是 GPT-4 是支持多轮对话的,另一方面是 GPT-4 支持更长的输入数据,下面讨论它们可能使用的技术:
- 支持多轮对话
GPT-4 支持连续对话,可能使用了 Transformer-XL,Transformer-XL 的重要改进是提出了片段递归的机制。片段递归机制类似于 Transformer 和 RNN 的结合体,它的核心思想是对于一个长度不限的变长数据,在计算的时候也是固定每个片段的长度并计算这个片段的特征,然后在计算下一个片段时将前面片段的特征加到当前片段上,从而让模型可以处理任意长度的特征。
- 支持更长的输入数据
GPT-3 就是使用的普通 Transformer 和 Sparse Transformer 的混合模式,所以 Sparse Transformer 也是非常有可能被 GPT-4 用来处理长输入文本的一个模型。Sparse Transformer 的特点是只关注 Top-k 个贡献最大的特征的状态,它使用稀疏注意力机制替代了 Transformer 的密集注意力。
GPT-4V 模型
GPT-4V 在处理任意交错的多模态输入和其能力的通用性方面,具有前所未有的能力,使 GPT-4V 成为一个强大的多模态通用系统。
另外,GPT-4V 独特的理解输入图像上绘制的视觉标记的能力,可以催生出新的人机交互方法,比如视觉参考提示(Visual Referring Prompting)。
输入模式(Input Modes)
GPT-4V 支持的输入模式包括:
- 作为单模型语言模型的文本输入
- 单个图像-文本对输入
- 使用交错的图像-文本对输入
- 使用多个图像作为输入
工作模式和提示技术
- 遵循文本指令(Following Text Instructions)
GPT-4V 的一个独特优势是其通用性,通过其强大的理解和遵循文本指令的能力实现。指令提供了一种自然的方式来定义和定制任意视觉语言用例所需的输出文本。
在输入端,GPT-4V 可以通过理解详细的指令来执行具有挑战的任务,比如,通过提供中间步骤的指令来更好地解释抽象推理问题。GPT-4V 从指令中学习新任务的能力,在适应各种未见过的应用和任务方面显示出巨大的潜力。
- 视点与视觉参考提示(Visual Pointing and Visual Referring Prompting)
GPT-4V 特别擅长理解和处理直接绘制在图像上的视点。鉴于在图像上绘制的灵活性,这种能力可以作为未来野外人机交互的一种自然方法。
通过探索一种新的提示方法,称为视觉参考提示(Visual Referring Prompting),它是一种人工智能技术,结合了自然语言处理和计算机视觉的能力,以理解和响应用户对特定视觉场景中的对象的描述。在这种技术中,模型需要根据自然语言提示(prompt)来定位和描述图像或视频中的特定对象或区域。Visual Referring Prompting 这种技术在增强现实、虚拟现实、机器人导航、智能助手等领域有广泛的应用潜力。
- 视觉 + 文本提示(Visual + Text Prompting)
视觉参考提示(Visual Referring Prompting)可以与其他图像文本提示顺畅地一起使用,呈现出一种细致的界面,简洁地表示出感兴趣的问题。GPT-4V 的通用性和灵活性使其具备了一种类似人类的多模态指令理解能力,以及适应未见过的任务的前所未有的能力。
- 上下文少样本学习(In-context Few-shot Learning)
GPT-4V 支持上下文少样本学习能力,通过给定几个上下文示例,而无需参数更新,就可以生成期望的推理输出。
目前,与 GPT-4V 相关的资料,更多出自论文《The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)》,该论文更多的是在探索 GPT-4V 的能力,以及在基于 GPT-4V 的能力能实现哪些可能的场景化应用。
想要更多的推测 GPT-4V 的技术要点和原理,可能更多需要详细了解该模型发布之前的几代模型的能力,尤其是 GPT-4。另外,GPT-4V 在视觉方面相关能力的逐步提升,尤其是人机互动,可能会是一个重要的点。
参考资源
- GPT: Improving Language Understanding by Generative Pre-Training
- Language models are few-shot learners
- The Illustrated GPT-2
- How GPT3 Works – Visualizations and Animations
- Positional encoding, residual connections, padding masks: covering the rest of Transformer components
- GPT-4 Technical Report
- https://openai.com/research/gpt-4
- https://openai.com/blog/gpt-4-api-general-availability
- https://zhuanlan.zhihu.com/p/621328705
- https://zhuanlan.zhihu.com/p/630548590
- https://zhuanlan.zhihu.com/p/680426850
- ChatGPT 原理与架构:大模型的预训练、迁移和中间件编程

本文基于署名-非商业性使用-相同方式共享 4.0许可协议发布,欢迎转载、使用、重新发布,但务必保留文章署名时延军(包含链接:http://shiyanjun.cn),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。如有任何疑问,请与我联系。
何时才能出现伴侣Ai
GPT-2中的相对位置编码请问有出处吗,在GPT-2的论文”Language Models are Unsupervised Multitask Learners”没有找到相关的说明,博主能补充一下吗,非常非常感谢!